
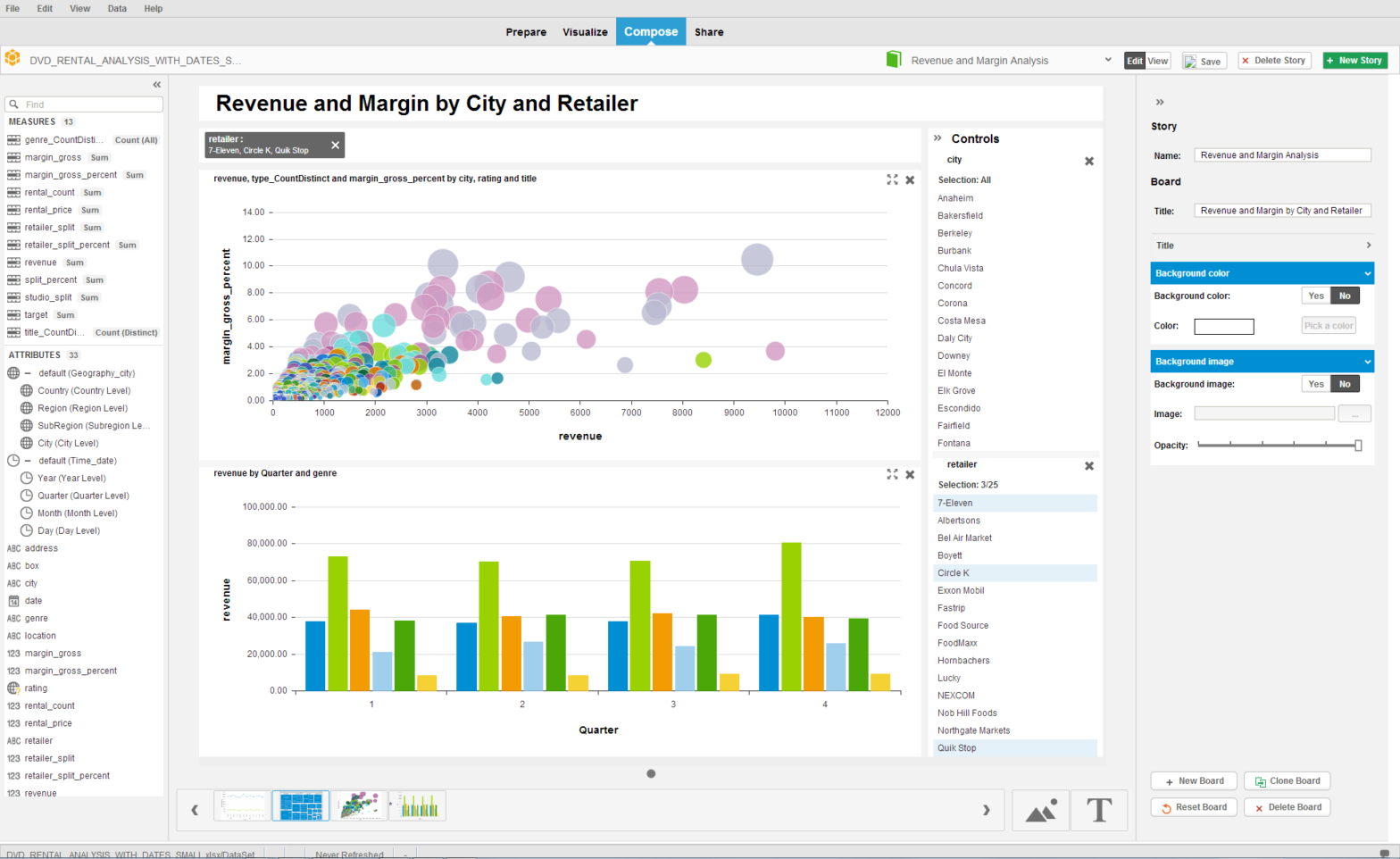
Lumira recently introduced a new concept called Blending. Blending allows Analytics to allow data from multiple datasets or fact tables to be displayed across a common dimension. This was a critical next step in Lumira’s evolution because often the job of an Analyst requires them to pull together multiple result sets into a single visualization. It’s […]
Category Archives: Lumira
Lumira | Predictive Analysis Troubleshooting: Hangs on the splash screen when starting…
I recently discovered an issue when leveraging both Lumira and Predictive Analysis 1.18 and it took me a while to debug the issue and so I wanted to share those results with you. The version of Lumira/Predictive Analysis I had installed on my desktop had a permanent key with a timeout and I didn’t realize […]
Migrating BEx-based Information Spaces to BusinessObjects 4.0
Sometimes in software it can feel that you take two steps forward and one step back. One example of this is with BEx-based Explorer Information Spaces when migrating from XI 3.1 to BO 4.0. In 4.0, SAP removed the ability to create information spaces against the legacy universe (unv) and instead required everyone to use […]
Using Explorer and Lumira with SAP BW
This is a quick post to let you know that there is an excellent whitepaper available which explains everything you need to know about leveraging Explorer and Visual Intelligence with SAP BW. Organizations must leverage some type of acceleration technology – either HANA or BWA. Here is the original article: http://www.saphana.com/docs/DOC-2943 Here is a link […]
Visual Intelligence – Resolving Start Up Issues
Enjoying Visual Intelligence? I am. Unfortunately however every once in a while something will go wrong. Most of the time stopping and restarting Visual Intelligence will fix the problem but sometimes not. One error I received recently was: Open document failed / The engine failed to start before timeout. Restart the application. (HDB 10005) Here […]